반응형
1.N8N 소개
아래 포스팅을 참고하자.
N8N 오픈소스 SW의 소개와 설치
1.N8N 소개와 개요N8N은 "Node-RED"나 "Zapier"처럼 워크플로우 자동화를 위한 툴이다. 가장 큰 특징은 오픈소스라는 점이다. MIT 라이선스를 기반으로 누구나 자유롭게 사용할 수 있고, 클라우드뿐만 아
jssvs.tistory.com
주요 특징
- 노드 기반 아키텍처: 직관적인 시각적 인터페이스를 통해 노드를 연결하여 워크플로우 구성
- Fair-code 라이선스: 대부분의 사용 사례에서 무료로 사용 가능
- Self-hosted 가능: 클라우드 또는 온프레미스 환경에서 직접 호스팅 가능
- 700개 이상의 통합: Slack, Google Sheets, Airtable, Notion 등 다양한 서비스와 연동
- 커스텀 노드 개발: JavaScript/TypeScript로 사용자 정의 노드 개발 가능
- 워크플로우 자동화: 스케줄링, 웹훅, API 호출 등을 통한 자동화 트리거 지원
2.Helm Chart를 이용한 n8n 설치 과정
A) Helm 리포지토리 추가
$ helm repo add n8n https://n8n-community.github.io/n8n-helm
$ helm repo update
B) chart value 작성
service:
type: NodePort
port: 5678
name: http
annotations: {}
main:
extraEnvVars:
N8N_SECURE_COOKIE: false
C) N8N 배포
#!/bin/bash
helm repo add community-charts https://community-charts.github.io/helm-charts
helm repo update
echo "install n8n by helm.."
VERSION="1.5.11"
helm upgrade --cleanup-on-fail \
--install my-n8n community-charts/n8n \
--namespace n8n \
--create-namespace \
--version $VERSION \
--values values.yaml
sleep 1
echo "install done.."
D) 외부 접속을 위한 ingress 생성
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: n8n-ingress
namespace: n8n
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing #public 오픈 시
alb.ingress.kubernetes.io/target-type: instance
alb.ingress.kubernetes.io/subnets: [서브넷 리소스]
alb.ingress.kubernetes.io/security-groups: [보안그룹 리소스]
alb.ingress.kubernetes.io/load-balancer-name: alb-dev-n8n
spec:
ingressClassName: alb
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: my-n8n
port:
number: 5678
반응형
'오픈 소스' 카테고리의 다른 글
| N8N 오픈소스 SW의 소개와 설치 (0) | 2025.05.06 |
|---|---|
| 쿠버네티스(kubernetes) - kubectl 명령어 정리/모음 (2) (0) | 2025.04.08 |
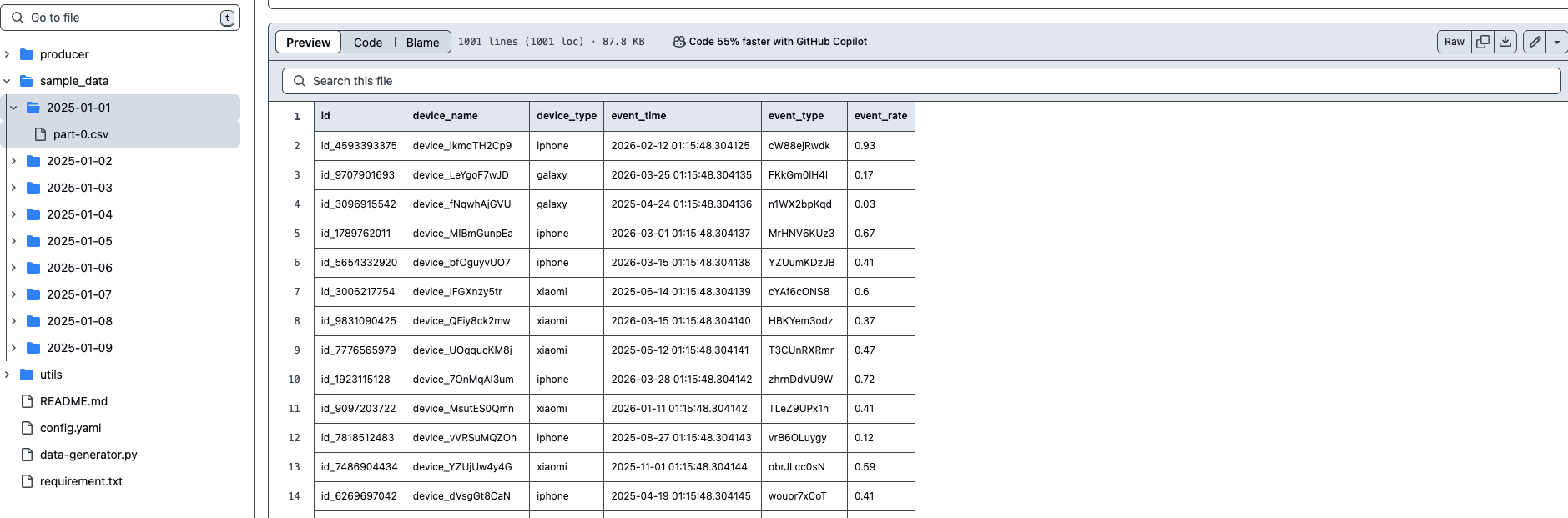
| 빅데이터 생성기 - BigdataSimpleGenerator (0) | 2025.04.01 |
| GPT 를 이용해서 동영상 쇼츠 제작해보기 (0) | 2025.03.25 |
| open-webui /ollama 를 이용해 내 컴퓨터에 ChatGPT 구축하기 (0) | 2024.09.20 |