반응형

빅데이터 처리 플랫폼을 EMR on EKS 로 도입하면서, 쿠버네티스 운영도 함께 하고 있다.
요즘엔 Spark 개발보다는 쿠버네티스 엔지니어링을 더 많이 하는 것 같아서, 정체성의 혼란이 올 때도 있지만..
나의 본질은 데이터 엔지니어링에 있다고 믿는다.
지난번에 한 번 정리한 글이 있는데, 새로운 명령어와 함께 다시 올려본다.
argoCD 사용자는 kubectl 을 쓸 일이 거의 없겠지만, 난 두개를 다 쓰고 있는 입장에서 kubectl 로 리소스를 직접 다루는게 더 재미있는
편이다. 아무튼.. 누군가에게 도움이 되길 바라며
1. 리소스 상태 및 로깅 관련
- 쿠버네티스 클러스터에서 발생하는 이벤트 로깅, pod , Node 의 리소스 상태 변화 순서로 확인하는게 좋다.
기본 이벤트 확인
$ kubectl get events
특정 네임스페이스 이벤트 확인
$ kubectl get events -n <namespace>
실시간 이벤트 감시
$ kubectl get events --watch
출력 형식 지정
$ kubectl get events -o wide
특정 Pod 상세 정보 확인
$ kubectl describe pod <pod-name>
네임스페이스 지정
$ kubectl describe pod <pod-name> -n <namespace>
모든 Pod 정보 확인
$ kubectl describe pod
Pod Logs (Pod 로그 확인)
$ kubectl logs <pod-name>
특정 컨테이너 로그 확인
$ kubectl logs <pod-name> -c <container-name>
실시간 로그 스트리밍
$ kubectl logs <pod-name> -f
시간별 로그 필터링
$ kubectl logs <pod-name> --since=1h
기본 노드 목록
$ kubectl get nodes
자세한 정보 포함
$ kubectl get nodes -o wide
JSON/YAML 형식으로 출력
$ kubectl get nodes -o json
노드 내 모든 리소스 정보 확인
$ kubectl describe node
2. 헬름 차트 관련 (helm chart)
- 헬름을 이용한 서비스 설치도 많이 하게 되는데, 기본 개념을 정리하면 다음과 같다
- 헬름 (helm) : 쿠버네티스 패키지 매니저
- 차트 (chart) : 쿠버네티스 리소스를 하나로 묶은 템플릿 (yaml 의 묶음)
- 헬름을 이용해 차트 기반으로 서비스를 배포할때 다음 용어도 알아두면 좋다
- 릴리즈 : 특정 차트를 클러스터에 설치한 인스턴스
- 레포지토리: 차트를 저장하고 배포하는 저장소
- 순서는 사용자가 정의해둔 차트에 value 값을 custom 하게 설정하고, 레포지토리를 추가한 다음. 릴리즈 버전과 함께 설치하면 된다.
레포지토리 추가
$ helm repo add <repo-name> <repo-url>
레포지토리 목록 확인
$ helm repo list
레포지토리 업데이트
$ helm repo update
차트 검색
$ helm search repo <keyword>
기본 차트 설치
$ helm install <release-name> <chart-name>
특정 네임스페이스에 설치
$ helm install <release-name> <chart-name> -n <namespace>
value 파일로 커스터마이징
$ helm install <release-name> <chart-name> -f values.yaml
직접 값 지정으로 설치
$ helm install <release-name> <chart-name> --set key1=value1,key2=value2
설치된 릴리즈 확인
$ helm list
차트 업그레이드
$ helm upgrade <release-name> <chart-name>
릴리즈 히스토리 확인
$ helm history <release-name>
롤백
$ helm rollback <release-name> <revision>
릴리즈 삭제
$ helm uninstall <release-name>
helm chart 조회는 아래에서 하면 된다.
Artifact Hub
Find, install and publish Cloud Native packages
artifacthub.io
반응형
'오픈 소스' 카테고리의 다른 글
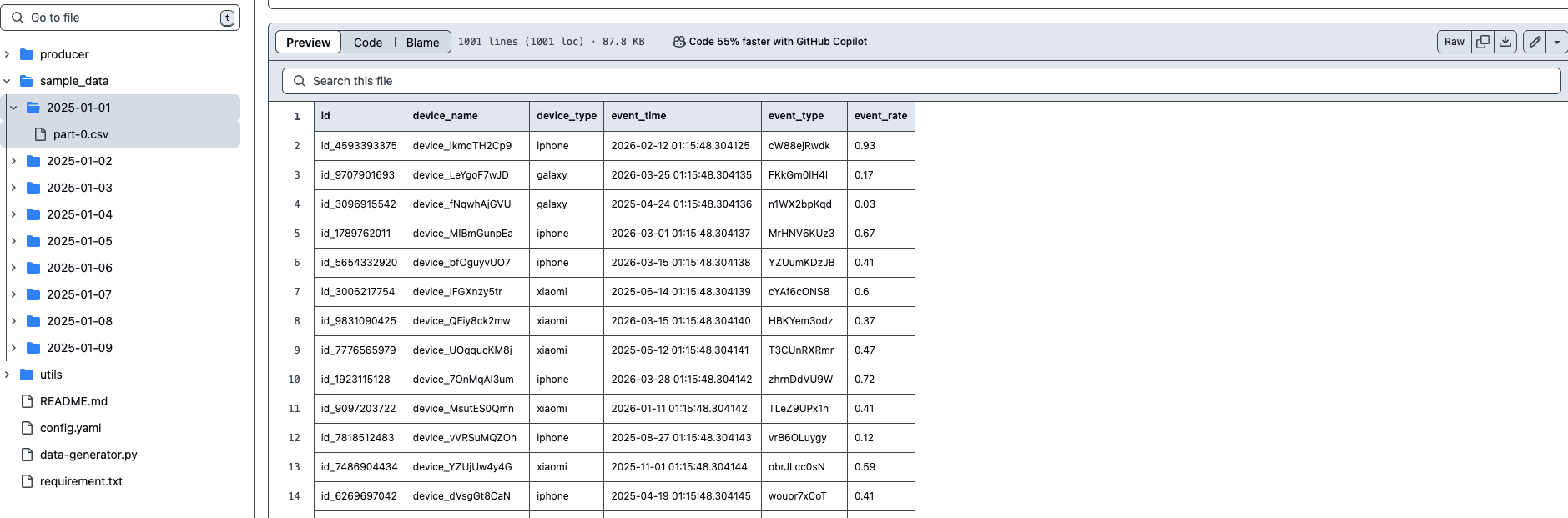
| 빅데이터 생성기 - BigdataSimpleGenerator (0) | 2025.04.01 |
|---|---|
| GPT 를 이용해서 동영상 쇼츠 제작해보기 (0) | 2025.03.25 |
| open-webui /ollama 를 이용해 내 컴퓨터에 ChatGPT 구축하기 (0) | 2024.09.20 |
| 프로메테우스(prometheus) 구성 및 기본 사용법 (0) | 2022.03.27 |
| zeppelin 을 이용한 spark 개발 환경 구성 및 사용법 (0) | 2021.09.05 |