1. Git-Sync란?
- Git-Sync 는 Kubernetes 클러스터 내에서 git repository 를 동기화하는 sidecar 기능이다 (1)
- airflow 와 같은 워크플로우 도구를 사용할 때, DAG 파일들을 git 에서 관리하고 있을 때 사용한다.
- helm 을 통한 쿠버네티스 배포 시에만 지원하는 기능으로 보인다.
2. 왜 GitSync 기능을?
- 일반적으로 python 으로 작성한 airflow dag 파일은 airflow component(worker, scheduler) 에서 access 할 수 있는 파일 시스템에 저장되어야 한다.
- git sync 기능을 사용하면, git repository 에 저장된 DAG 파일을 kubernetes pod 내부에 동기화 할 수 있다.
- 반대로 git sync 를 사용하지 않는다면, DAG 파일을 kubernetes pod 에 복사하는 방식을 사용해야 한다.
- s3 로 부터 주기적으로 sync 를 받는 sidecar 컨테이너를 개발
- efs 와 같은 네트워크 파일 시스템을 사용
3. Git-Sync 사용하기
절차
- git repository 를 생성한다.
- 2가지 인증 방식 중 한 가지를 선택한다.
- 선택한 인증방식의 credential 을 준비한다.
- 인증 정보를 쿠버네티스 secret(시크릿) 으로 생성한다
- helm chart 에서 git-sync 를 활성화 한다. (2)
인증 2가지 방식 소개
- SSH 프로토콜을 이용한 인증 방식 (Github 기준 )
- HTTPS 프로토콜을 이용한 인증 방식
A.SSH 프로토콜을 이용한 인증 방식
SSH 키 생성
$ ssh-keygen -t rsa -b 4096 -C "jssvs@test.com"
# 복제할 키 문자열
$ cat ~/.ssh/id_rsa.pub
Git에 SSH 키 등록

쿠버네티스 시크릿 리소스 생성
kubectl create secret generic airflow-git-ssh-secret --from-file=gitSshKey=~/.ssh/id_rsa -네임스페이스
helm chart 값 작성
..... 생략
dags:
gitSync:
enabled: true
repo: git@git repository url
branch: main
rev: HEAD
depth: 1
maxFailures: 0
subPath: ""
sshKeySecret: airflow-git-ssh-secret
.... 생략
B.HTTPS 프로토콜을 이용한 인증 방식
PAT 생성 (Setting -> Developer settings -> Personal access tokens -> Generate new token)
시크릿 yaml 작성하기
** 주의 : username 과 pat 는 base64 인코딩을 해서 저장해야 한다.
** 또 주의: linux 에서 echo 를 이용할 경우 -n 옵션을 추가하여 뉴라인을 제거한다
apiVersion: v1
kind: Secret
metadata:
name: git-credentials
data:
GIT_SYNC_USERNAME: github username
GIT_SYNC_PASSWORD: PAT 비밀번호
GITSYNC_USERNAME: github username
GITSYNC_PASSWORD: PAT 비밀번호
helm chart값 작성
.....
dags:
gitSync:
enabled: true
repo: https://git repository url
branch: main
rev: HEAD
depth: 1
maxFailures: 0
subPath: ""
credentialsSecret: git-credentials
.....
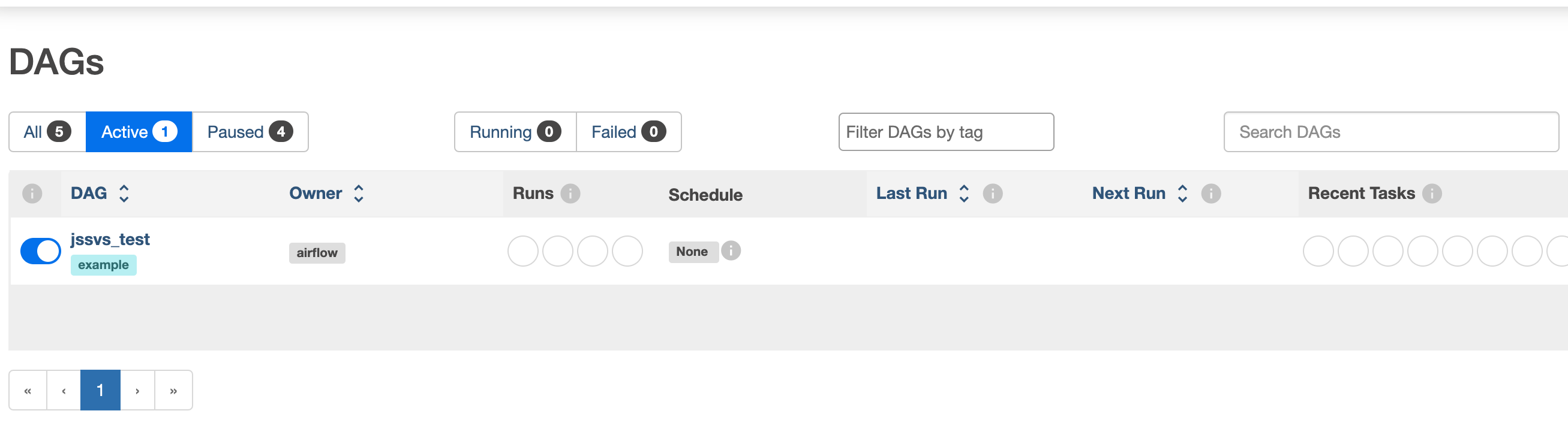
helm 을 이용한 설치 후 git-syn-init 컨테이너에서 아래와 같은 로그가 찍혔다면 성공이다.
동작 스크린샷
4. Reference
(1) https://airflow.apache.org/docs/helm-chart/stable/manage-dags-files.html#using-git-sync
Manage DAGs files — helm-chart Documentation
airflow.apache.org
(2) https://artifacthub.io/packages/helm/apache-airflow/airflow
airflow 1.15.0 · apache-airflow/apache-airflow
The official Helm chart to deploy Apache Airflow, a platform to programmatically author, schedule, and monitor workflows
artifacthub.io
'Data Engineer' 카테고리의 다른 글
| 쿠버네티스 Yunikorn 스케쥴러 (0) | 2025.02.20 |
|---|---|
| airflow - Dag Factory (0) | 2025.02.18 |
| 쿠버네티스 -스테이트풀셋(statefulset)를 이용해 ElasticSearch 배포 (0) | 2024.12.29 |
| 쿠버네티스 - 디플로이먼트(deployment)를 이용해 MySQL 배포 (1) | 2024.12.09 |
| 파이썬 데일리코딩 - 다이나믹 프로그래밍 (0) | 2024.11.25 |